RDP 2005-03: Property Owners in Australia: A Snapshot Appendix B: Econometric Methodology
May 2005
In Section 3.1, the two-part model was briefly introduced. Here, this framework is introduced more formally and the reasons for its choice are discussed.
As noted in Puhani (2000), the two-part model can be formally represented by


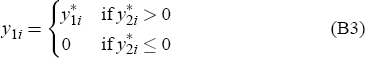
In principle, y1 is the observed variable, while 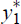 and
and 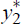 are unobserved. Equations
(B2) and (B3) together are a model of a binary choice as to whether the observed
variable is positive or zero, which can be estimated using a probit model.
Equation (B2) represents the modelling of the latent variable for y1,
namely ,
conditional on y1 being positive. As such, this
part of the model can be estimated by applying OLS estimation to the sub-sample
over which the observed variable is positive.
are unobserved. Equations
(B2) and (B3) together are a model of a binary choice as to whether the observed
variable is positive or zero, which can be estimated using a probit model.
Equation (B2) represents the modelling of the latent variable for y1,
namely ,
conditional on y1 being positive. As such, this
part of the model can be estimated by applying OLS estimation to the sub-sample
over which the observed variable is positive.
The conditioning in the second part of the model specification distinguishes the two-part model from the widely-used selection model due to Heckman (1976, 1979). The latter allows the whole population's behaviour to be assessed, rather than just the sub-sample. However, since it is actual behaviour that this paper seeks to model, it can be argued that the conditional expectation is of more interest than the unconditional expectation.[18] While marginal effects are able to be determined from the Heckman model, the two-part model provides these in a more direct manner.
Apart from the interpretation arguments in favour of the two-part model, there are some technical grounds on which it is preferable to the selection model. Despite the Heckman selection model's popularity in the literature, some deficiencies have been identified in its application. As noted by Leung and Yu (1996) and Puhani (2000), the Heckman selection model is susceptible to collinearity problems between the explanatory variables in the value equation and the inverse
Mills ratio. Leung and Yu (1996) suggested, on the basis of Monte Carlo simulations, that serious collinearity problems may exist if the condition number of the matrix of explanatory variables (including the constant) and the inverse Mills ratio exceeds 20.[19] If this is the case, the two-part model would be preferred to the Heckman selection model, since the Heckman model estimates tended to be unstable and performed much worse than the two-part model. This holds even in the case where the Heckman selection model is the ‘true’ model for the data. It also accords with Puhani's (2000) suggestion that if collinearity problems are present, the two-part model may be the most robust and simple-to-calculate estimator.
To confirm the validity of the two-part modelling approach, the condition number test was applied to the four groups of models after using the variables from the preferred two-part model specifications to estimate selection models.[20] For all four models, the condition number exceeded 20, thus supporting the decision to use the two-part model. It was surprising, however, that, when estimating the selection models using full information maximum likelihood, only the ownership-value models showed significant selection effects, while the gearing-leverage models suggested there was no selection effect.
Puhani (2000) also documents that the estimated coefficients of the Heckman selection model are sensitive to violations of the assumption of bivariate normality of the error terms.[21] While semi-parametric and non-parametric procedures have been developed for estimating selection models without the need for strong distributional assumptions, the two-part model has the advantages of interpretability and simplicity of estimation.
Other techniques could also be used to examine the questions addressed in this paper. Manrique and Ojah (2003) use an endogenous switching regression model to examine primary and secondary home ownership and expenditure. Although the ownership decisions may be linked, the motives for holding other residential property appear to differ between Spain and Australia. The authors note that for Spain the ownership of second residences is likely to be for consumption purposes as holiday homes. For Australia, other residential property appears to be more widely used for investment purposes. Because of these differences, and due to the greater simplicity of the framework, the choices of owning the different types of property were estimated separately.
Footnotes
This is an argument similar to that made in Duan et al (1983) with regard to health care expenditures. [18]
This condition number test is based on the test developed for OLS regressions by Belsley, Kuh and Welsch (1980). [19]
For the purposes of the condition number test, the selection models were estimated using Heckman's two-step procedure, in line with Leung and Yu (1996). [20]
This was another reason cited by Duan, Manning Jr, Morris and Newhouse (1983) for preferring the two-part modelling strategy for examining health care expenditures. [21]